i2018n - Internationalisation in 2018
O For A Thousand Tongues to type
Peter Burkimsher, 2018-06-19
peterburk@gmail.com
Contents
|
Introduction> Have you ever used a computer in another language? What does the 關機 button do? > I have 100 localisations; that must be enough. Text looks cleaner, let's get rid of the icons. If you like pretty graphs and want to change the world, this article is for you! You'll find 9 graphs about languages of by famous brands, 2 datasets of bilingual strings, and 2 more graphs about Chinese dialects. I did this side project because I'm looking a job, hopefully in New Zealand or Canada, possibly Australia. I'm currently working for a memory card manufacturer in Taiwan, logging and analysing testing data about microSD cards. I've been a foreigner all my life, and I'm trying to find a country to call home. Please tell me where I'm welcome! There are a lot of graphs. If you work for one of these companies, you can send them to a director! I can also make some graphs for you and your company! (e.g. Coca-Cola, Pepsi, McDonalds, or other multinational brands). |
Microsoft Windows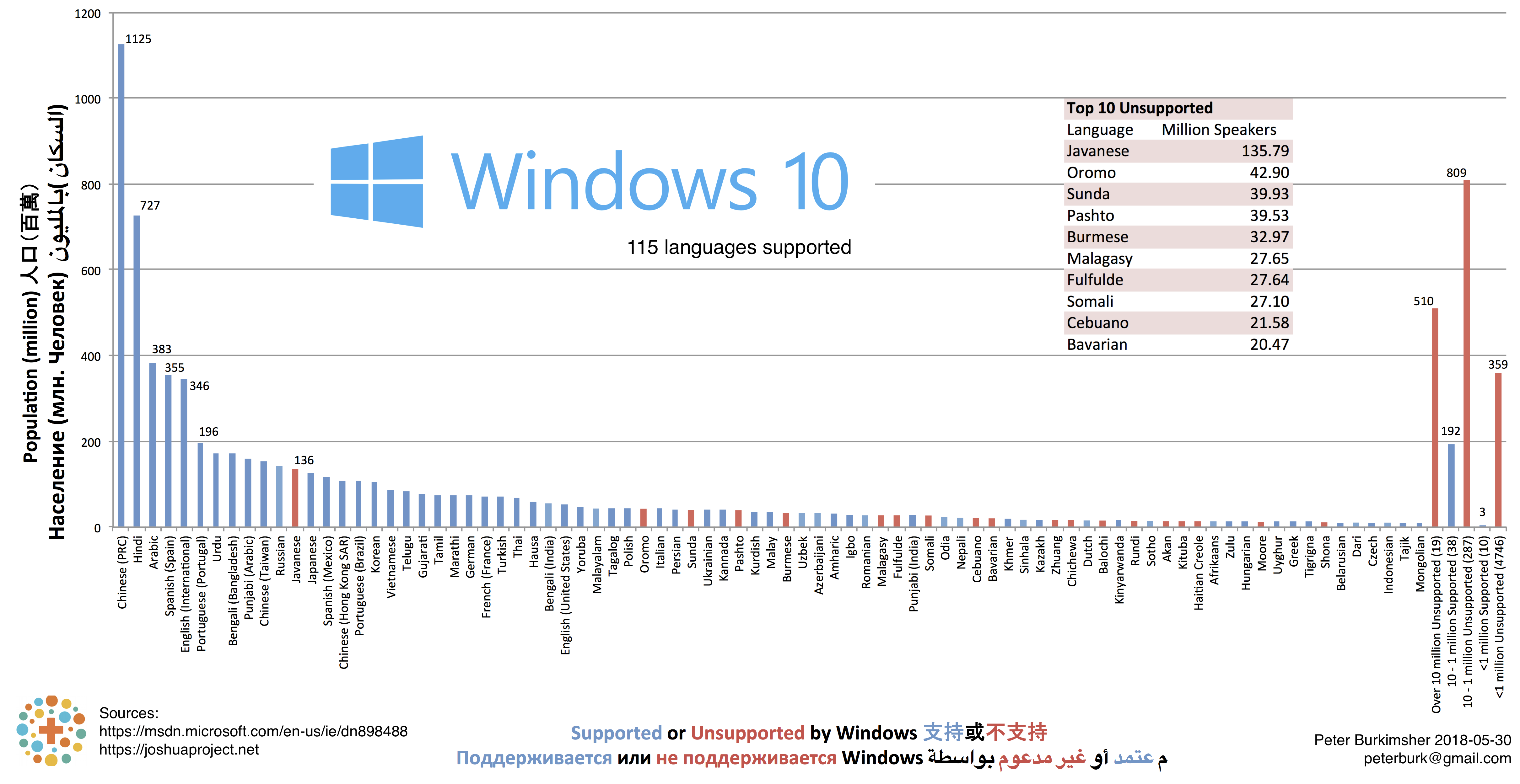 Figure 1 - Windows Languages over 10 million
This is the first of many graphs! Click it to see a larger version.
The most striking feature is the curve: an exponential decrease. A lot of people speak Chinese, Hindi, Arabic, Spanish, and English.
The 115 Windows languages include 78.9% of the world population. What about the other 21.1% = 1,712,940,580 people?
Unsupported languages are marked in red. Each looks small, but they add up.
On the right-hand side, there are aggregate bars. It is good to make blue bars taller and red bars shorter.
"Over 10 million Unsupported (19)" means 19 languages with over 10 million speakers do not have a localised Windows version.
The data label "510" by the red bar means that by adding those 19 languages, it would reach 510 million people.
That's a lot of people. It's more than the number of native English speakers!
The red inlaid table shows the Top 10 Unsupported languages. These should be a priority for Microsoft's translation team.
There are 98-135 million Javanese speakers, which is 10x more than the 9-10 million Java programmers.
I'd like to make more graphs like this with programming languages, if I can find a good data source.
There are 10 Windows languages with fewer than 1 million speakers:
Figure 1 - Windows Languages over 10 million
This is the first of many graphs! Click it to see a larger version.
The most striking feature is the curve: an exponential decrease. A lot of people speak Chinese, Hindi, Arabic, Spanish, and English.
The 115 Windows languages include 78.9% of the world population. What about the other 21.1% = 1,712,940,580 people?
Unsupported languages are marked in red. Each looks small, but they add up.
On the right-hand side, there are aggregate bars. It is good to make blue bars taller and red bars shorter.
"Over 10 million Unsupported (19)" means 19 languages with over 10 million speakers do not have a localised Windows version.
The data label "510" by the red bar means that by adding those 19 languages, it would reach 510 million people.
That's a lot of people. It's more than the number of native English speakers!
The red inlaid table shows the Top 10 Unsupported languages. These should be a priority for Microsoft's translation team.
There are 98-135 million Javanese speakers, which is 10x more than the 9-10 million Java programmers.
I'd like to make more graphs like this with programming languages, if I can find a good data source.
There are 10 Windows languages with fewer than 1 million speakers:
Maltese (655,560), Maori (642,700), Norwegian Nynorsk (576,996), Icelandic (438,800), Luxembourgish (424,100), Cherokee (302,000), Irish (279,700), Scottish Gaelic (64,400), Inuktitut (35,000), Catalan - Valencian (13,000).
The bias towards European languages is probably because of pressure from the EU. This is not a bad thing, per se; it should be a call for other regional groups (ASEAN, ECOWAS, ODECA, UNASUR, Arab League, Pacific Union) to exert the same pressure that the EU does.
To give all languages equal priority (I'm looking at you, 13,000 Valencian speakers) would require translating Windows to 2670 languages.
Most of those sound small, but Norwegian? It turns out there are two dialects: Bokmål and Nynorsk. Both are supported by Windows.
I got my population data from JoshuaProject, which doesn't separate those dialects. Therefore I used the Wikipedia value of 86.3% Bokmål to estimate the populations speaking each dialect.
Dividing dialects means that values may vary between graphs. For example, Windows separates English (International) and English (United States).
I modified the data, subtracting the population of English speakers in the United States.
Microsoft calls it English (International), and English (United Kingdom) in other places. I'm biased because my passport is British, so I showed favouritism and made my native dialect look larger.
 Figure 2 - Windows Languages 10 - 1 million
Why did I stop at 10 million? The long tail of this data continues much further.
For Windows, I plotted the next 325 languages, and clearly the graph is dominated by red bars.
I haven't drawn this graph for the other data sources, because I think the aggregate bars on the Over 10 Million graph shows the outcome well enough.
When managers want to actually do something about supporting these languages, they can download my Excel spreadsheets.
Figure 2 - Windows Languages 10 - 1 million
Why did I stop at 10 million? The long tail of this data continues much further.
For Windows, I plotted the next 325 languages, and clearly the graph is dominated by red bars.
I haven't drawn this graph for the other data sources, because I think the aggregate bars on the Over 10 Million graph shows the outcome well enough.
When managers want to actually do something about supporting these languages, they can download my Excel spreadsheets.
|
Apple macOS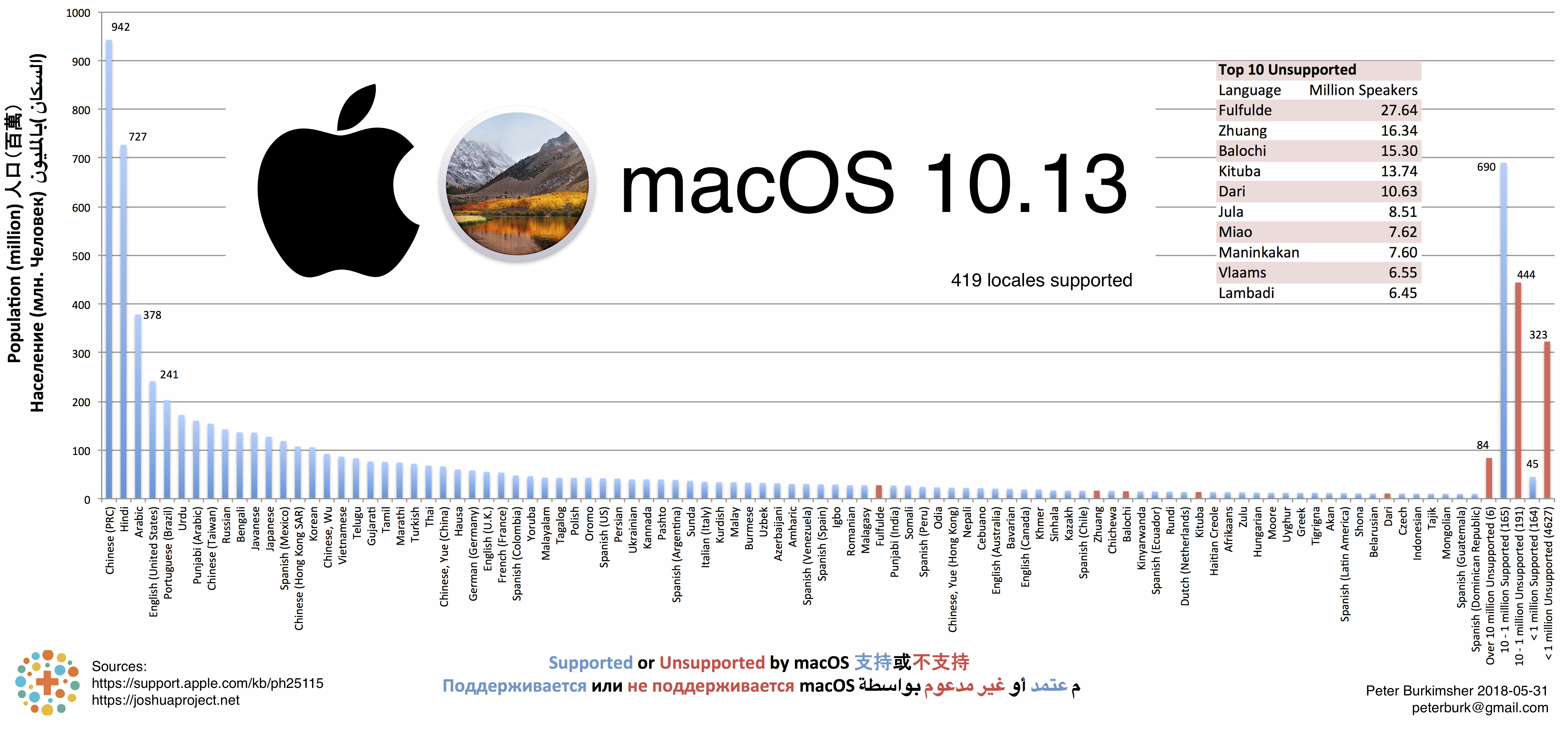 Figure 3 - macOS Locales over 10 million
A lot more dialects are shown in the macOS locales. There are Italian + Italian Italy/Switzerland, as well as Norwegian + Norwegian Bokmål/Nynorsk, Portuguese + Portuguese (Brazil/Portugal), and Spanish (Mexico/Spain/more).
Because of the way I split the data for estimating the populations of these dialects, some languages look much smaller in this graph.
There are even locales for Chinese dialects, such as Shanghainese and Sichuan Yi! We'll discuss those more later in Appendix 2: Chinese.
There is a locale for Hindi (Latin) which is not used, but there is no equivalent Chinese (Pinyin) locale.
Windows has some advantages over macOS. There are different Bengali (Bangladesh) and Bengali (India) in Windows, but only one in macOS.
There is a Dari version of Windows, but not macOS.
There are 12 locales supported on macOS that are not on JoshuaProject: Zuni, Sanskrit, Arapaho, Manx, Hupa, Interlingua, Cornish, Esperanto, Latin, Klingon, Geez, Lojban. Some of these are constructed auxiliary languages with no native speakers, others are extinct.
I considered German (Austria) to be Bavarian.
While splitting dialects in this data, I learned that Turkmen and Uzbek have used Latin, Cyrillic, and Arabic scripts!
Serbian uses Cyrillic and Latin.
Kazakhstan changed their alphabet in February 2018 from Cyrillic to Latin, and they don't have Windows or macOS in Latin yet.
At a first glance, the macOS data looks very impressive! The blue bars are taller than the red bars. But appearances can be deceiving.
Although 419 languages are listed in System Preferences > Language & Region, most of them don't have any actual string translations.
It is much easier to scrape strings from a Mac, because the data is in Contents/Resources/*.lproj/Localizable.strings as an XML.
When I tried to extract the data, I discovered a surprising reality: Finder isn't actually translated into those languages.
Figure 3 - macOS Locales over 10 million
A lot more dialects are shown in the macOS locales. There are Italian + Italian Italy/Switzerland, as well as Norwegian + Norwegian Bokmål/Nynorsk, Portuguese + Portuguese (Brazil/Portugal), and Spanish (Mexico/Spain/more).
Because of the way I split the data for estimating the populations of these dialects, some languages look much smaller in this graph.
There are even locales for Chinese dialects, such as Shanghainese and Sichuan Yi! We'll discuss those more later in Appendix 2: Chinese.
There is a locale for Hindi (Latin) which is not used, but there is no equivalent Chinese (Pinyin) locale.
Windows has some advantages over macOS. There are different Bengali (Bangladesh) and Bengali (India) in Windows, but only one in macOS.
There is a Dari version of Windows, but not macOS.
There are 12 locales supported on macOS that are not on JoshuaProject: Zuni, Sanskrit, Arapaho, Manx, Hupa, Interlingua, Cornish, Esperanto, Latin, Klingon, Geez, Lojban. Some of these are constructed auxiliary languages with no native speakers, others are extinct.
I considered German (Austria) to be Bavarian.
While splitting dialects in this data, I learned that Turkmen and Uzbek have used Latin, Cyrillic, and Arabic scripts!
Serbian uses Cyrillic and Latin.
Kazakhstan changed their alphabet in February 2018 from Cyrillic to Latin, and they don't have Windows or macOS in Latin yet.
At a first glance, the macOS data looks very impressive! The blue bars are taller than the red bars. But appearances can be deceiving.
Although 419 languages are listed in System Preferences > Language & Region, most of them don't have any actual string translations.
It is much easier to scrape strings from a Mac, because the data is in Contents/Resources/*.lproj/Localizable.strings as an XML.
When I tried to extract the data, I discovered a surprising reality: Finder isn't actually translated into those languages.
 Figure 4 - Finder Languages over 10 million
Finder only has translations into 35 languages! The red bars are much taller.
Other parts of macOS have more languages (e.g. Siri has Yue Chinese), but it's clear that Apple is lagging behind Microsoft for general OS language support.
I guess that there are more languages in iOS, but my iPhone 4S is too old to use iOS 11 so I haven't graphed that data.
It's not all bad news for Apple though.
Apple shows the drop-down list of languages in their native script, not translated. This is important when trying to change a Chinese-language computer to English, for example. Choosing "English" instead of "英文" is easier if you can't read the translation of your own language. Windows fails at this.
It's easier to change the system language in macOS, because those 35 languages are installed by default.
This uses disk space, and Monolingual is a program that can remove them if you really need those megabytes.
Windows requires installing language packs, which are specific to the OS version you use and require Administrator access.
I haven't made a string comparison table as I did for Windows above, because you should be able to just change the language if you need.
However, if you still want a dataset of strings from the macOS System folder, here it is: MacOSStrings.zip
Figure 4 - Finder Languages over 10 million
Finder only has translations into 35 languages! The red bars are much taller.
Other parts of macOS have more languages (e.g. Siri has Yue Chinese), but it's clear that Apple is lagging behind Microsoft for general OS language support.
I guess that there are more languages in iOS, but my iPhone 4S is too old to use iOS 11 so I haven't graphed that data.
It's not all bad news for Apple though.
Apple shows the drop-down list of languages in their native script, not translated. This is important when trying to change a Chinese-language computer to English, for example. Choosing "English" instead of "英文" is easier if you can't read the translation of your own language. Windows fails at this.
It's easier to change the system language in macOS, because those 35 languages are installed by default.
This uses disk space, and Monolingual is a program that can remove them if you really need those megabytes.
Windows requires installing language packs, which are specific to the OS version you use and require Administrator access.
I haven't made a string comparison table as I did for Windows above, because you should be able to just change the language if you need.
However, if you still want a dataset of strings from the macOS System folder, here it is: MacOSStrings.zip
|
Ubuntu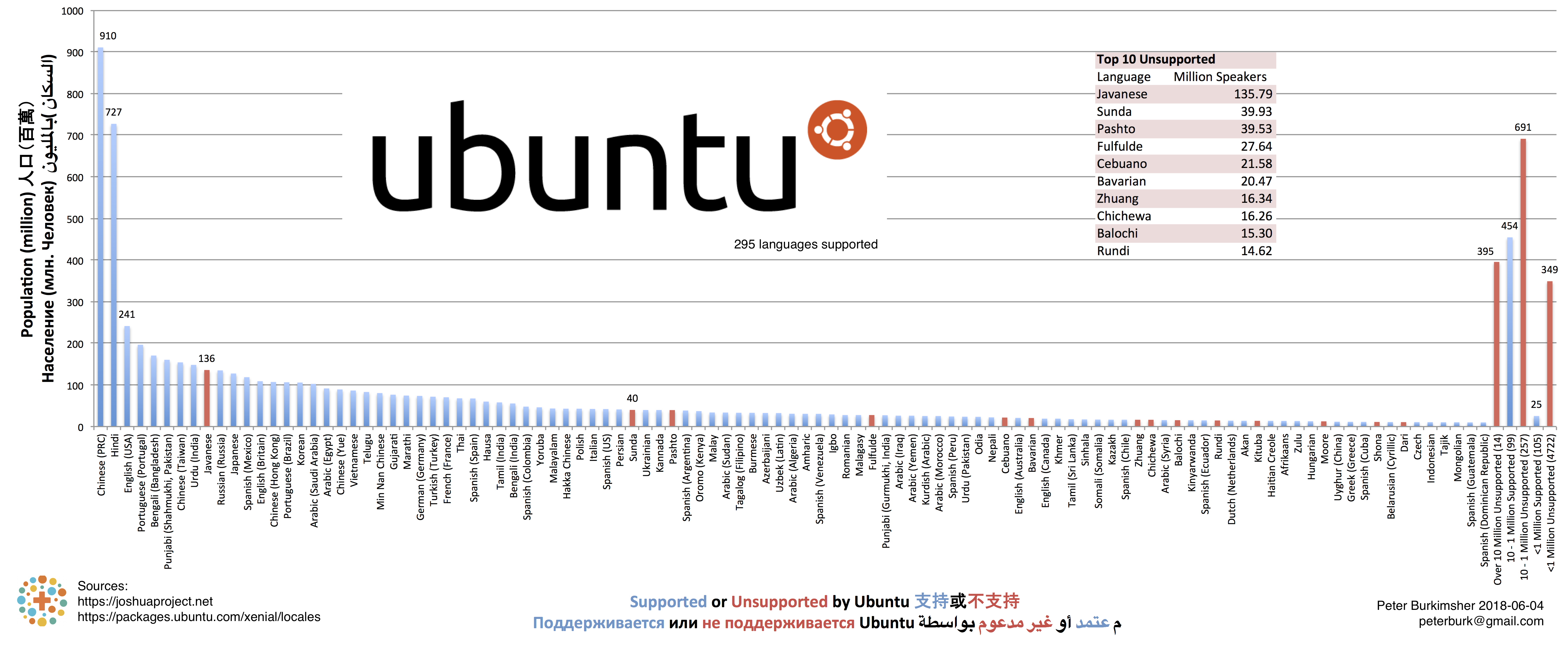 Figure 5 - Ubuntu Languages over 10 million
Ubuntu has a lot of locales listed, but like macOS and Finder, maybe they don't all have full translations.
There's a few quirks about this data. In 1989, ISO changed iw_IL to he_IL. Ubuntu has both. There are also 4 Ge'ez locales, even though it is only in use as a liturgical language.
There's a lot of Chinese locales in Ubuntu, which we'll discuss more later in Appendix 2: Chinese.
There is a different locale cmn_TW for Hanzi collation (sort order), and zh_TW, which are both Mandarin.
Terence Eden wrote a good blog post describing how difficult it is to sort alphabetically or numerically in Chinese.
In macOS, this is implemented differently to the locale, but it is also controlled in System Preferences > Language & Region.
Windows uses the Unicode sort order by default.
Ubuntu is named after a Nguni Bantu word meaning "humanity", or "I am because we are".
Of that language family, Ubuntu (the OS) supports the 4 largest Nguni languages: Zulu (13.3M), Xhosa (9.70M), Ndebele (4.37M), and Swati (3.71M), but not Lala (4100).
Figure 5 - Ubuntu Languages over 10 million
Ubuntu has a lot of locales listed, but like macOS and Finder, maybe they don't all have full translations.
There's a few quirks about this data. In 1989, ISO changed iw_IL to he_IL. Ubuntu has both. There are also 4 Ge'ez locales, even though it is only in use as a liturgical language.
There's a lot of Chinese locales in Ubuntu, which we'll discuss more later in Appendix 2: Chinese.
There is a different locale cmn_TW for Hanzi collation (sort order), and zh_TW, which are both Mandarin.
Terence Eden wrote a good blog post describing how difficult it is to sort alphabetically or numerically in Chinese.
In macOS, this is implemented differently to the locale, but it is also controlled in System Preferences > Language & Region.
Windows uses the Unicode sort order by default.
Ubuntu is named after a Nguni Bantu word meaning "humanity", or "I am because we are".
Of that language family, Ubuntu (the OS) supports the 4 largest Nguni languages: Zulu (13.3M), Xhosa (9.70M), Ndebele (4.37M), and Swati (3.71M), but not Lala (4100).
|
Google Translate
Assamese (India), Cherokee, Dari, Inuktitut (Latin, Canada), K'iche' (Guatemala), Kinyarwanda, Konkani (India), Odia (India), Quechua (Peru), Setswana (South Africa), Tatar (Russia), Turkmen, Uyghur, Valencian, Wolof
On a more optimistic note, if you're a programmer, you can easily be the first to make a machine translation tool for these languages!
You can use the Windows Strings dataset above as a bilingual dictionary to get started.
Some languages are supported by Google Translate but not Windows. If you're a developer at Microsoft, have a close look at these and decide whether to support them.
Google Translate not Microsoft Windows (19):
Cebuano, Chichewa, Corsican, Esperanto, Frisian, Haitian Creole, Hawaiian, Hmong, Javanese, Latin, Malagasy, Myanmar (Burmese), Pashto, Samoan, Shona, Somali, Sundanese, Yiddish.
It gets worse when you consider dialects. Punjabi can be written in Gurumukhī (India) or Shahmukhi scripts (Pakistan, Arabic). Google Translate does not support the Shahmukhi script for Punjabi, which might upset 160 million people.
Dialects are not shown on the graphs unless they're supported, because I want the red bars to appear larger.
Some dialects are supported by Google Translate, such as Chinese (Simplified) and Chinese (Traditional). Therefore it is appropriate to request for these to be added. This includes English (United Kingdom), which is personally important to me.
Instead of translating "喜愛" as "favorite", I'd rather make you happy by adding the "u" - making "favourite".
Microsoft Windows Dialects not Google Translate (16):
Bangla (Bangladesh), Bangla (India), Chinese (Hong Kong SAR), Central Kurdish, English (United Kingdom), French (Canada), Norwegian Nynorsk (Norway), Portuguese (Brazil), Punjabi (Arabic), Serbian (Cyrillic, Bosnia and Herzegovina), Serbian (Cyrillic, Serbia), Serbian (Latin, Serbia), Spanish (Mexico).
|
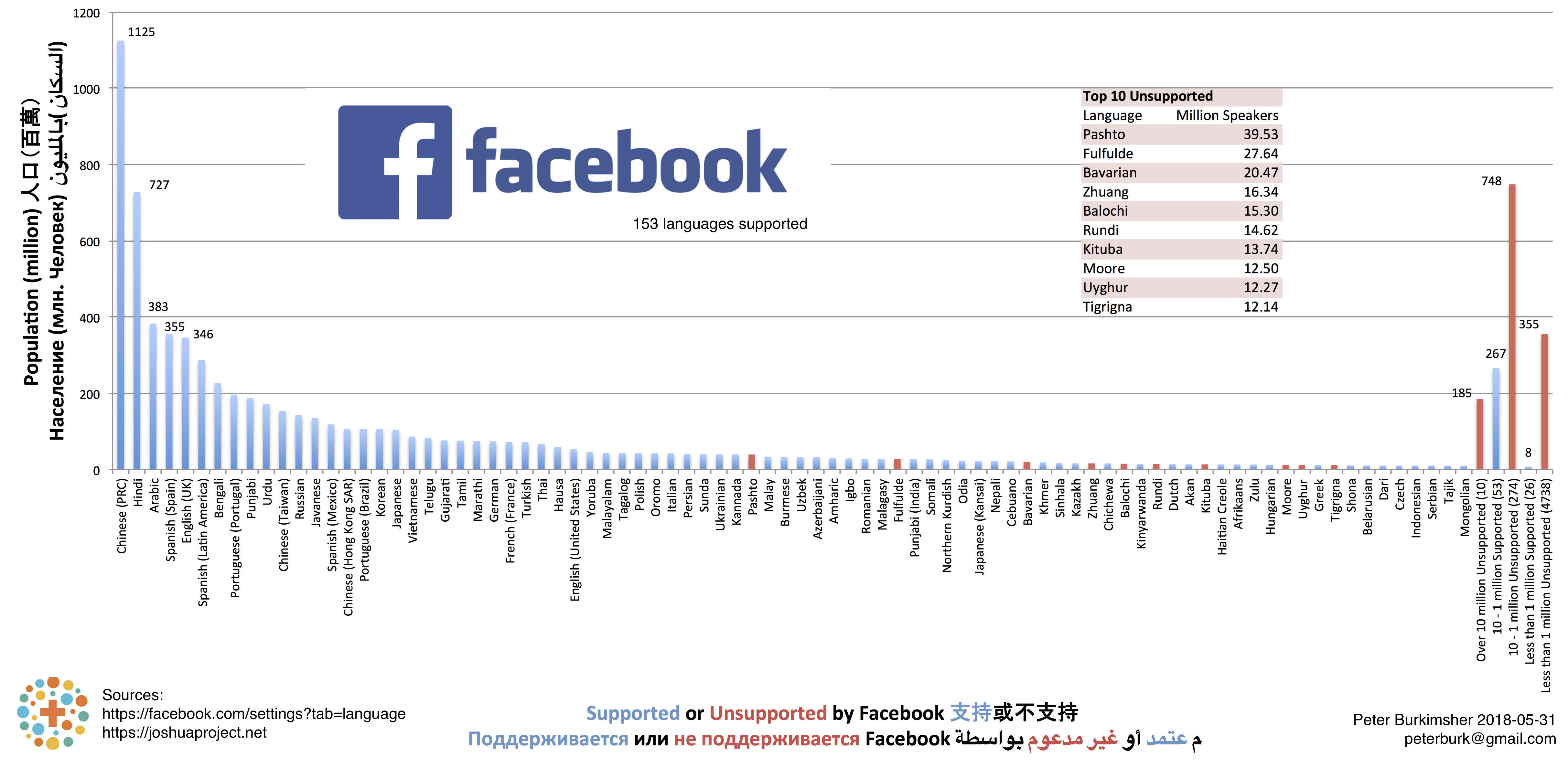 Figure 6 - Facebook Languages over 10 million
Facebook has some interesting translations. Even though there are no native speakers of the following languages, you can set your Facebook language to these!
¿ƃuoɹʍ oƃ ʎlqᴉssod plnoɔ ʇɐɥM
Figure 6 - Facebook Languages over 10 million
Facebook has some interesting translations. Even though there are no native speakers of the following languages, you can set your Facebook language to these!
¿ƃuoɹʍ oƃ ʎlqᴉssod plnoɔ ʇɐɥM
Ancient Greek, English (Pirate), English (uʍop əpısdՈ), Esperanto, Klingon, Latin, Leet Speak, Sanskrit
On a side note, I know many people here in Taiwan who choose to use the English versions of Facebook/Windows/macOS in order to improve their English.
Therefore the number of speakers of a language might not correspond to their desired usage patterns.
It also means that if you work for Facebook, you can't simply look at the language setting or location to determine a person's desired locale.
This mismatch of locale, location, and language is what causes me to see lots of adverts in Chinese. I can't read them, but that's fine by me!
I'm not a fan of adverts. Some marketer is probably losing money because of me though.
Facebook also recently introduced an auto-translation feature onto the news feed. This disregards the fact that some people are bilingual.
It's useful to have a Translate button, but I don't think it should be activated by default.
|
Wikipedia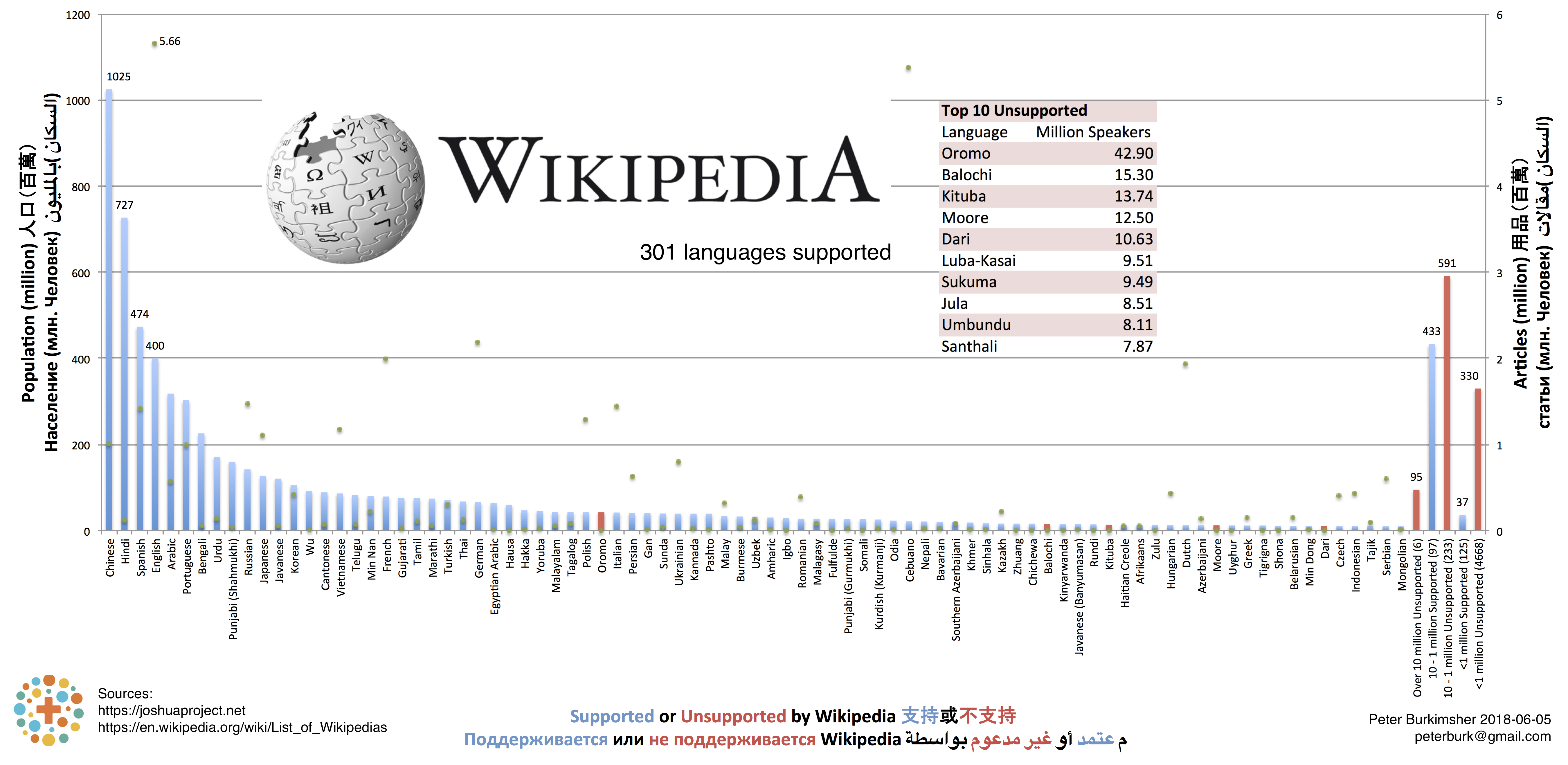 Figure 7 - Wikipedia Languages over 10 million
The Wikipedia graph has an extra axis! Green dots indicate the number of articles.
From this, it's obvious that there's many articles in English, but surprisingly few in Chinese and Hindi.
I imagine that most Chinese speakers are reading Baidu Baike instead.
Cebuano has 5.38 million articles, and this is disproportionately large.
It's not because of Wikipedia Zero, which doesn't operate in the Philippines. There are only 5 admins, and I thought that something unusual is happening there.
The data dump is only 1.8 GB, which is much smaller than the 15 GB for English.
Most seem to be related to locations, plants, and animals, and were created by Lsjbot.
I then found out from the Size of Wikipedia page that Cebuano, Swedish, and Waray are all written by bots.
I'd like to congratulate Wikipedia for supporting many dialects, including Minnan/Hokkien/Taiwanese/台語, which we'll discuss more later in Appendix 2: Chinese.
Figure 7 - Wikipedia Languages over 10 million
The Wikipedia graph has an extra axis! Green dots indicate the number of articles.
From this, it's obvious that there's many articles in English, but surprisingly few in Chinese and Hindi.
I imagine that most Chinese speakers are reading Baidu Baike instead.
Cebuano has 5.38 million articles, and this is disproportionately large.
It's not because of Wikipedia Zero, which doesn't operate in the Philippines. There are only 5 admins, and I thought that something unusual is happening there.
The data dump is only 1.8 GB, which is much smaller than the 15 GB for English.
Most seem to be related to locations, plants, and animals, and were created by Lsjbot.
I then found out from the Size of Wikipedia page that Cebuano, Swedish, and Waray are all written by bots.
I'd like to congratulate Wikipedia for supporting many dialects, including Minnan/Hokkien/Taiwanese/台語, which we'll discuss more later in Appendix 2: Chinese.
|
International BaccalaureateFigure 8 - IB Languages over 10 million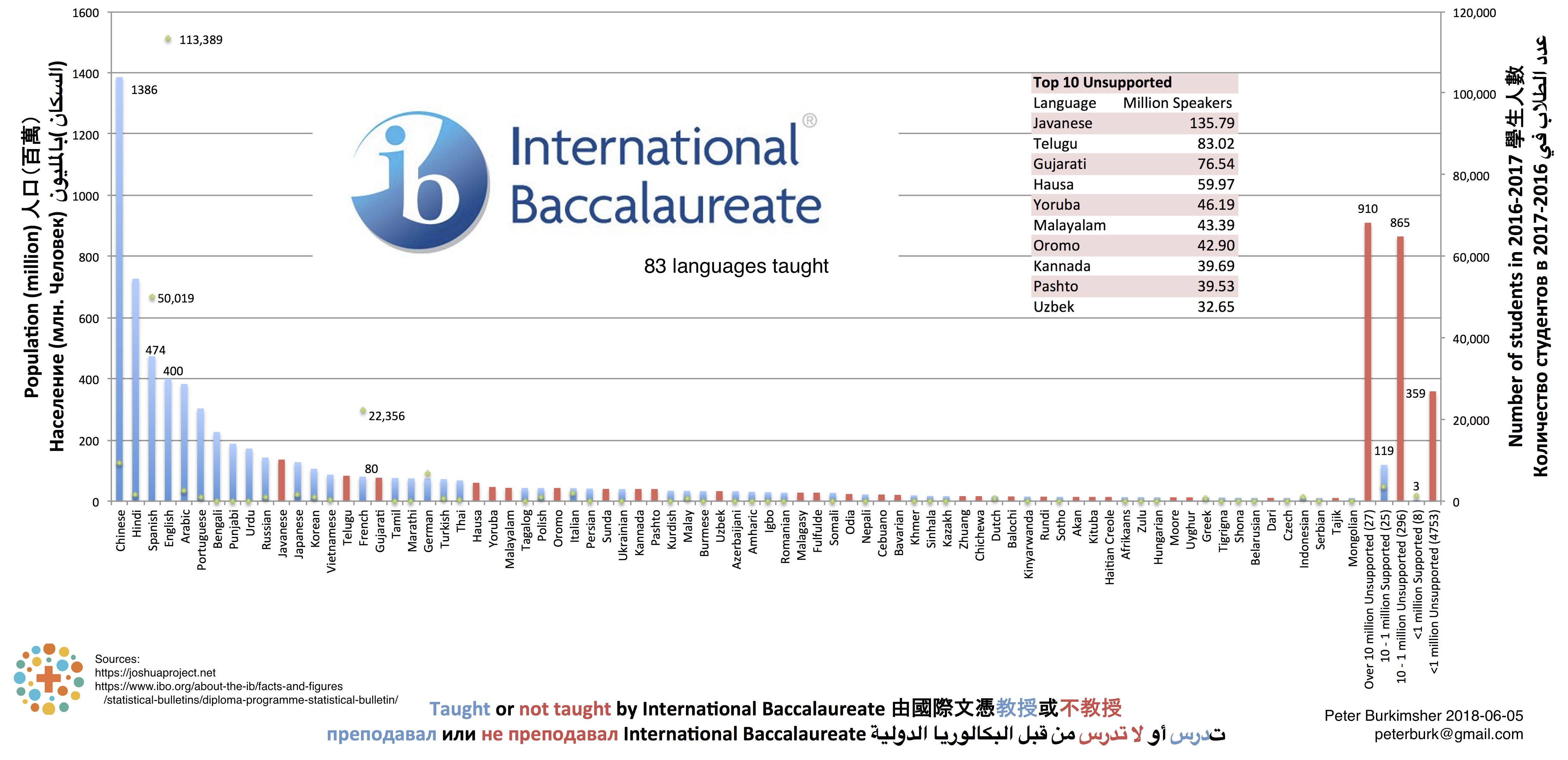 This is particularly interesting to find the more popular second languages. There's a second axis here too, with green dots showing the number of students.
The International Baccalaureate is a high school exam taught at over 4900 schools around the world.
I studied at the International School of Geneva, and graduated with 39 points (out of 45) in 2007.
My subjects were Higher Level Computer Science (7), Physics (6), and Maths (5), and Standard Level Economics (7), English (6), and French B Anticipé (7), with 1 bonus point.
When choosing my subjects, I thought carefully about whether to study Chinese or Korean instead of French, because I thought it would be more useful.
However, I was sure I could get a good grade in French because I lived in France.
Students with high grades in French class were encouraged to get a bilingual diploma.
I managed to keep my grades low in class (usually about 5) so I'd be allowed to take the exam for French as a second language.
I was also allowed to take the French exam a year early, which gave me more free time in my final year to
This is particularly interesting to find the more popular second languages. There's a second axis here too, with green dots showing the number of students.
The International Baccalaureate is a high school exam taught at over 4900 schools around the world.
I studied at the International School of Geneva, and graduated with 39 points (out of 45) in 2007.
My subjects were Higher Level Computer Science (7), Physics (6), and Maths (5), and Standard Level Economics (7), English (6), and French B Anticipé (7), with 1 bonus point.
When choosing my subjects, I thought carefully about whether to study Chinese or Korean instead of French, because I thought it would be more useful.
However, I was sure I could get a good grade in French because I lived in France.
Students with high grades in French class were encouraged to get a bilingual diploma.
I managed to keep my grades low in class (usually about 5) so I'd be allowed to take the exam for French as a second language.
I was also allowed to take the French exam a year early, which gave me more free time in my final year to
Assyrian, Maori, Dhivehi (Maldives), Icelandic, Dzongkha (Bhutan), Irish, Classical Greek, Latin.
I'd also like to mention that the IBO is recruiting a Tamil examiner.
The language was supported in 2016 but was not offered in 2017, probably as a result of not finding a suitable candidate.
The statistical bulletins of May and November 2017 are made of screenshots, which makes copy-pasting impossible.
The 2016 data included real text in the PDF, so I used the November 2016 and May 2017 exams to reduce the amount of transcribing I had to do.
The exams are offered twice a year because the summer holiday is at a different time in the southern hemisphere.
Some languages are only available during the May exam session, so students needing to re-sit would be required to wait a whole year instead of only 6 months.
|
Bible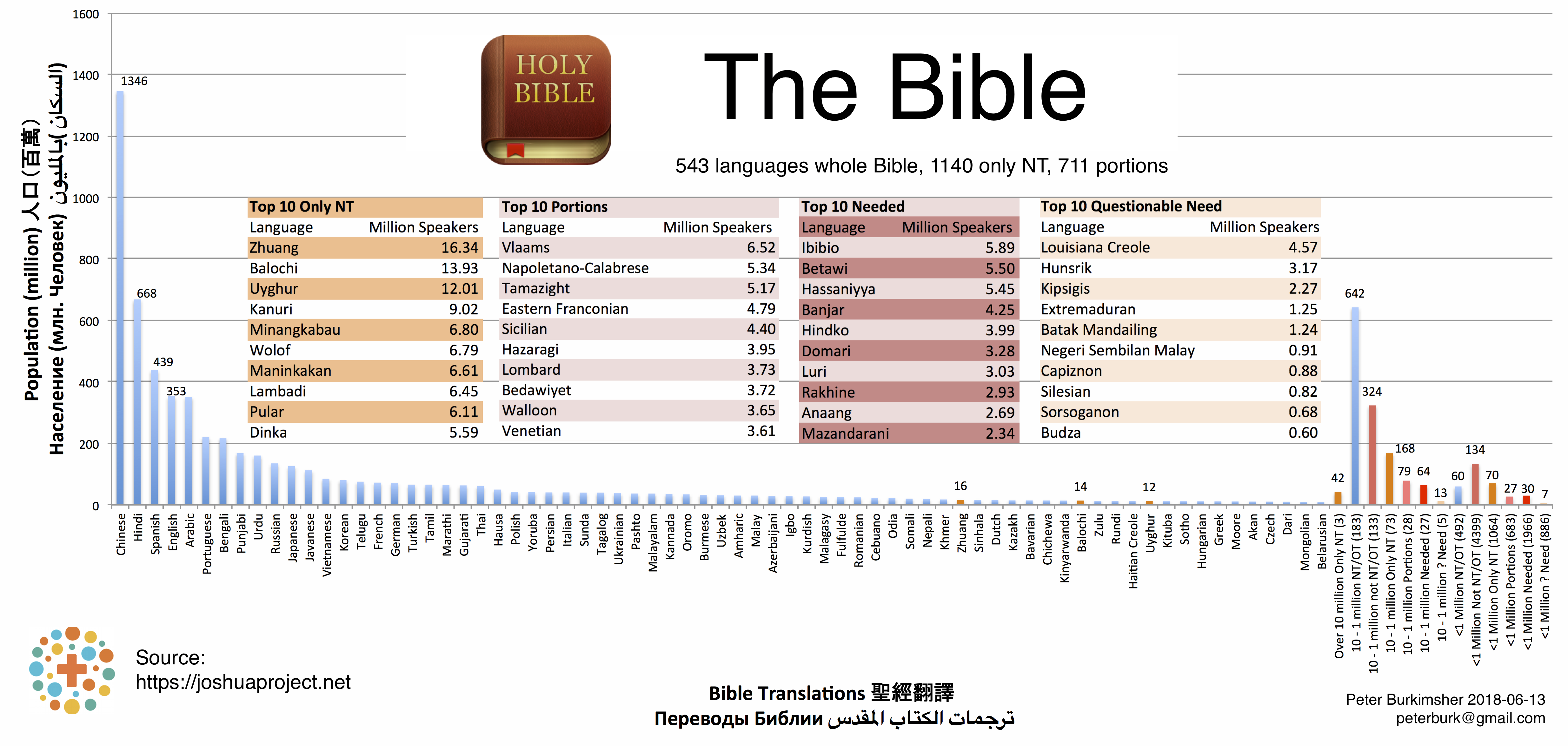 Figure 9 - Bible Languages over 10 million
This graph has more shades of red. "Only NT" means that only the New Testament has been translated.
"Portions" means that some parts are available, but not a whole testament. Apparently someone is working on it.
"Needed" represents languages that don't even have a partial translation, and nobody has even started.
"Questionable Need" is a few languages that might not be so important, because their populations are likely to be bilingual.
The blue bar is taller than the red bars, but only because of the extra divisions. 6.8 billion people speak the languages with a transaltion, but 1 billion people still lack a full Bible translation.
The Bible is the most-translated book in the world.
The original texts were written in Hebrew, Greek, and Aramaic, and were first compiled as a single volume in the Latin Vulgate in 382.
Protestant Christians have been continually working on new Bible translations since Luther's 1522 translation into German, although some monks made other translations earlier.
Roman Catholics have also joined the effort, especially since replacing Latin Mass with vernacular languages at the Second Vatican Council in the 1960s.
I wish that I could encourage the Bible translation teams over at Wycliffe to make O For a Thousand Tongues to Sing the most-translated song in the world.
Technological breakthroughs encourage more translations. Gutenberg brought the printing press from China to Europe in the 1450s, then typewriters came in 1874, computers with word processing arrived in 1979 (WordPerfect), and Microsoft Word in 1983.
I think that the 2010 iPhone 4 was the first smartphone with a camera and screen good enough to reproduce legible text.
That's when I started transitioning to reading the Bible electronically, although I still prefer to read on paper when possible.
Translations can also affect culture. Twi became the prestige dialect of Akan because it was used for Bible translation.
I've been teaching myself Chinese by reading the Bible and listening to translated worship songs.
I also started building a 台語 translator despite the lack of a dictionary, because I can look up words in the Bible.
Computer words aren't in the Bible though, and that's why I needed to do this project to get a wider corpus.
Music is an excellent way to learn, because it's not boring to listen to the same song many times, and it's easy for me to learn lyrics.
It also helps culturally, because I can sing along in church.
Figure 9 - Bible Languages over 10 million
This graph has more shades of red. "Only NT" means that only the New Testament has been translated.
"Portions" means that some parts are available, but not a whole testament. Apparently someone is working on it.
"Needed" represents languages that don't even have a partial translation, and nobody has even started.
"Questionable Need" is a few languages that might not be so important, because their populations are likely to be bilingual.
The blue bar is taller than the red bars, but only because of the extra divisions. 6.8 billion people speak the languages with a transaltion, but 1 billion people still lack a full Bible translation.
The Bible is the most-translated book in the world.
The original texts were written in Hebrew, Greek, and Aramaic, and were first compiled as a single volume in the Latin Vulgate in 382.
Protestant Christians have been continually working on new Bible translations since Luther's 1522 translation into German, although some monks made other translations earlier.
Roman Catholics have also joined the effort, especially since replacing Latin Mass with vernacular languages at the Second Vatican Council in the 1960s.
I wish that I could encourage the Bible translation teams over at Wycliffe to make O For a Thousand Tongues to Sing the most-translated song in the world.
Technological breakthroughs encourage more translations. Gutenberg brought the printing press from China to Europe in the 1450s, then typewriters came in 1874, computers with word processing arrived in 1979 (WordPerfect), and Microsoft Word in 1983.
I think that the 2010 iPhone 4 was the first smartphone with a camera and screen good enough to reproduce legible text.
That's when I started transitioning to reading the Bible electronically, although I still prefer to read on paper when possible.
Translations can also affect culture. Twi became the prestige dialect of Akan because it was used for Bible translation.
I've been teaching myself Chinese by reading the Bible and listening to translated worship songs.
I also started building a 台語 translator despite the lack of a dictionary, because I can look up words in the Bible.
Computer words aren't in the Bible though, and that's why I needed to do this project to get a wider corpus.
Music is an excellent way to learn, because it's not boring to listen to the same song many times, and it's easy for me to learn lyrics.
It also helps culturally, because I can sing along in church.
|
ConclusionThe world is a very diverse place. Recommending that people replace icons with text and "translate those into the 72 languages that Gmail supports" will isolate a lot of the market who must use a second language to operate a computer. I'm a fan of skeuomorphic design, even though it's no longer the trend. Adding only a few more languages can make a lot of people very happy. Installing Windows language packs is hard, but they support more languages than macOS. Changing from video to photo mode on a Chinese-language iPhone was easy in iOS 6, but became more difficult for me when the icons were replaced by text. For future work, I'd like to make graphs of iOS and Android localisations, extract the strings from other apps (e.g. Office), and estimate future populations of these languages based on demographic data. |
Appendix 1: Developer documentationThe title, i2018n, is a pun on the term "i18n", which is short for "internationalisation" (there are 18 letters between i and n). I extracted the strings from shell32.dll using a scraper I built using sample code from StackOverflow. For some languages, I couldn't install the language pack using lpksetup.exe, so I reinstalled Windows from the ISO and used a slightly different scraper. If you download too many ISOs, Microsoft will ban your IP for 3 hours or more, giving Error 715-123130. I used a spare computer to work around that problem. I then had 157 GB of ISOs, 1.59 GB of language pack CAB files, and 11.45 GB for each virtual machine. Installing language packs took a whole day, unattended. Reinstalling Windows from ISOs for the other 38 languages took 2 whole days of manual interaction. Arabic is written right to left, and this can be really confusing. The Windows installer for Thai is in English. The fonts for Japanese and Chinese make ASCII characters look awful. Setting a password is optional. Some of the ISOs from Microsoft are Win10_1511, others are Win10_1803. Some languages let you select a version (Home, Professional, Ultimate), others don't. Running virtual machines uses a lot of power, and your MacBook Pro will get pretty hot. German and French have different keyboard layouts, which makes typing a username or product key a bit harder. Thankfully there's always an English (ASCII) keyboard option. There are 107 text files, one for each language. The file names correspond to the integer value of the language ID. My data scrape is missing 3 languages, because the links are broken on MSDN: 1074 Setswana (South Africa), 7194 Serbian (Cyrillic, Bosnia and Herzegovina), 10266 Serbian (Cyrillic, Serbia). All other language packs are available, although you must remove everything before download.windowsupdate.com to make the URL work. There are also 5 languages that are no longer used: 1158 K'iche' (Guatemala), 3098 Serbian (Cyrillic, Serbia), 2074 Serbian (Latin, Serbia), 2141 Inuktitut (Latin, Canada), 3076 Chinese (Hong Kong SAR). Although there are 65536 possible keys, only 4410 actually have values. A word of warning: parsing and aligning the data is not trivial. There are many special characters, mixed right-to-left scripts, and stray newlines that confuse most programming languages, including my first parser in Python. If you don't believe me, just try to open 16821.txt in TextWrangler and sort it. Building the table above required making a parser that can grep for the string keys I need. I extracted the icons from shell32.dll and imageres.dll by renaming the DLL to 7z, opening it with Keka, and going to the hidden .rsrc folder, looking through for the icon I want, and converting each ICO file to a PNG. |
Appendix 2: Chinese DialectsAfter you've tried learning Chinese, everything else seems easy. As part of Pingtype, I've gathered a lot of bilingual English/Chinese data. As well as the train timetable, Bible, restaurant menu, 200 Christian song lyrics, and movie subtitles on the website, I have much more on my local machine, including bilingual English/台語 songs. Please contact me if you're interested in that. In addition to Mandarin, I'm personally interested in Minnan/Hokkien/Taiwanese/台語 and Hakka, because my girlfriend's mum speaks 台語 and her dad speaks Hakka. The difference between English (United States) and English (United Kingdom) is relatively minor, although we joke about the words we misunderstand. That's not true of Chinese dialects. Cantonese and Taiwanese are not mutually intelligible with Mandarin.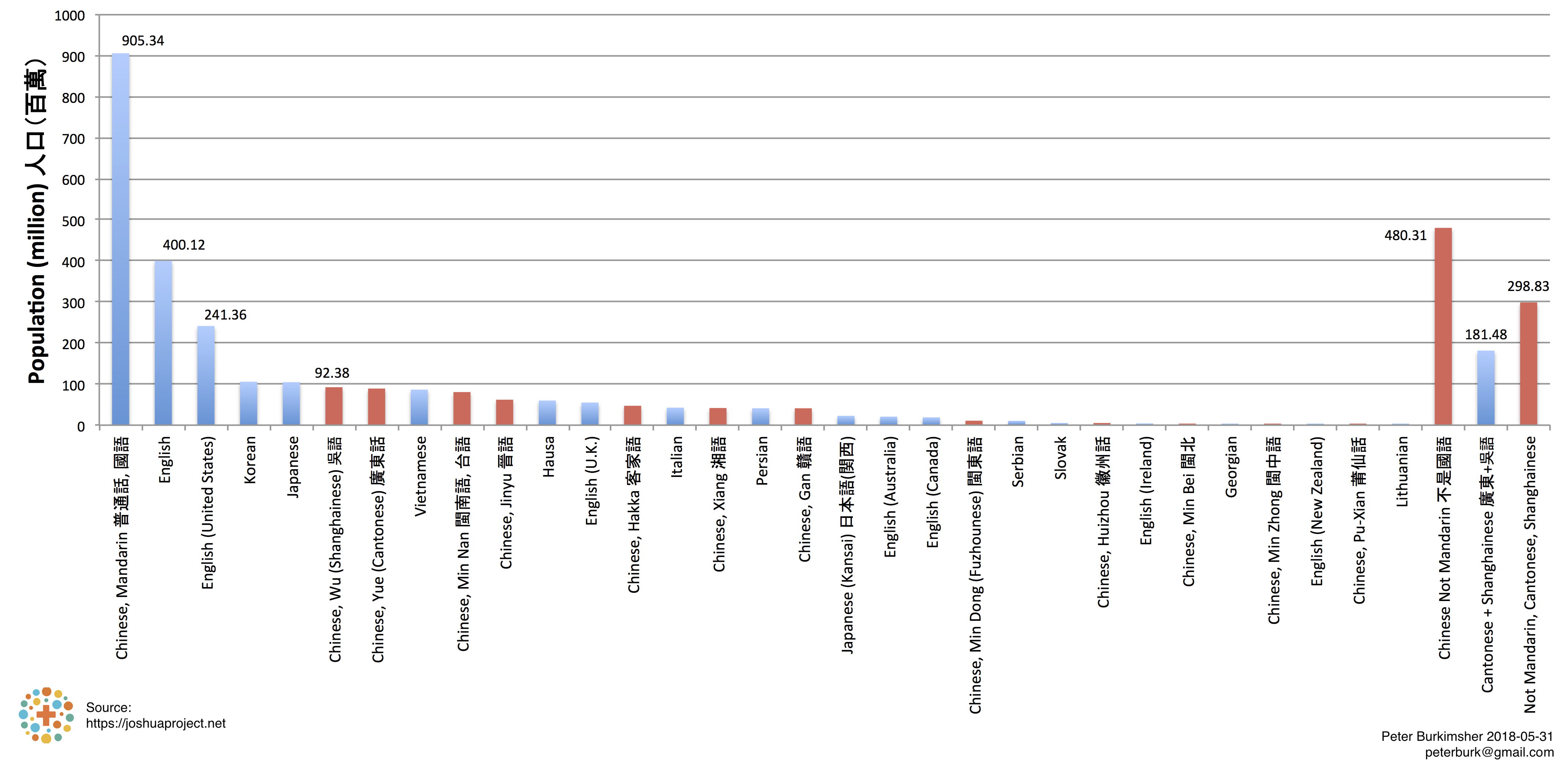 Figure 10 - All Chinese Dialects
When graphing all the Chinese dialects, Mandarin clearly dominates. However, the non-Mandarin dialects combined have a total of 480 million speakers, which is more than English.
Cantonese and Shanghainese are shown separately on this graph, because they're the largest two dialects, and also are listed in the macOS locales (although there is no actual OS translation for them in Finder).
Figure 10 - All Chinese Dialects
When graphing all the Chinese dialects, Mandarin clearly dominates. However, the non-Mandarin dialects combined have a total of 480 million speakers, which is more than English.
Cantonese and Shanghainese are shown separately on this graph, because they're the largest two dialects, and also are listed in the macOS locales (although there is no actual OS translation for them in Finder).
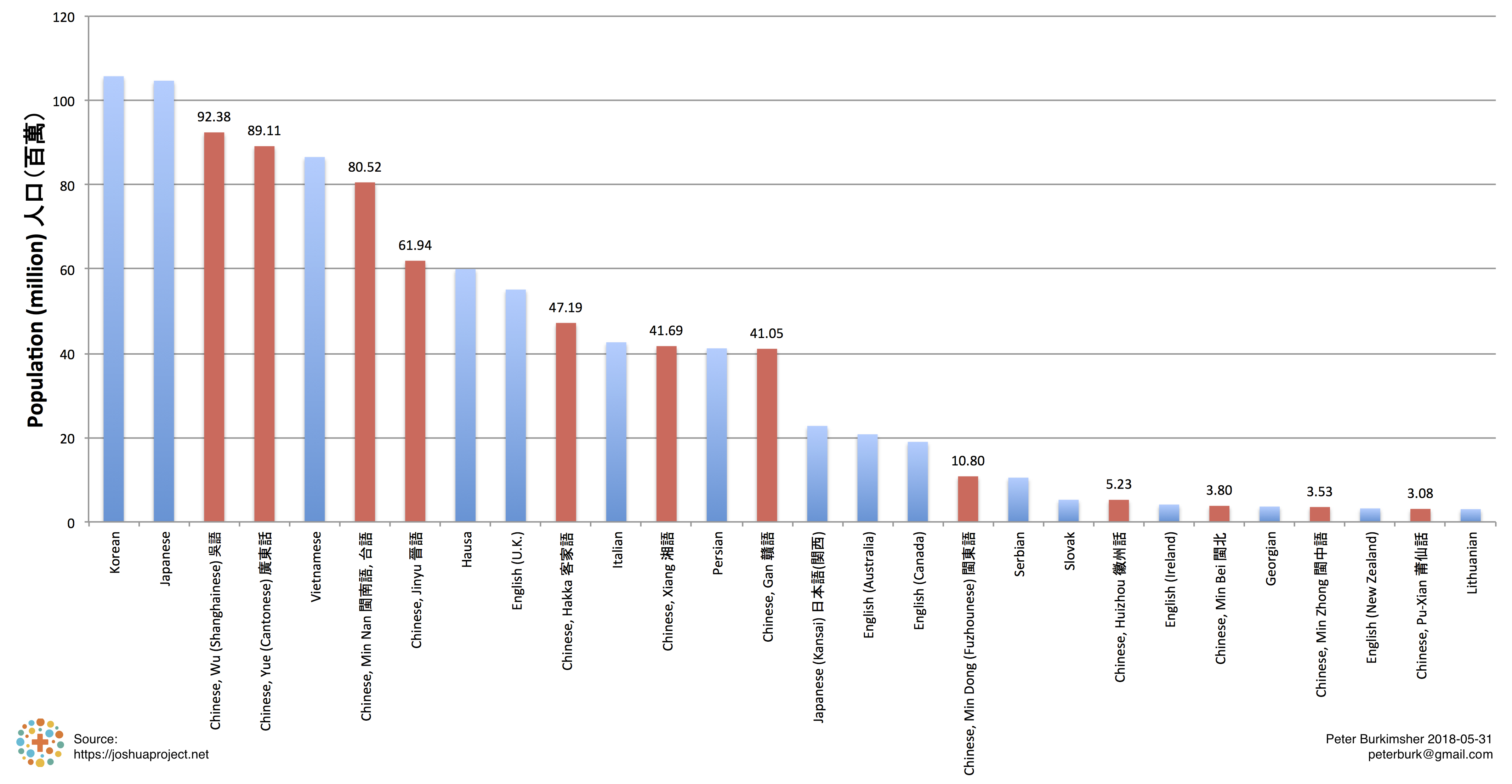 Figure 11 - Non-Mandarin Chinese Dialects
Comparing the dialects to other world languages also gives an idea of the scale. Facebook has a translation for Japanese (Kansai), despite the population being a third of the size of the number of speakers of Minnan/Hokkien/Taiwanese/台語.
There is no Google Translate for 台語, but I'm a fan of 滅火器 Fire EX. and I want to understand their lyrics.
Therefore I added basic support for 台語 into Pingtype, and I wrote another script that looks up the words from their lyrics in the Bible and hymn book.
From the bilingual data, I can then build a dictionary. I also included some data from Maryknoll and Taigi FHL.
I've made one example video with the help of some friends translating, but I hope to continue developing Pingtype so I don't have to wait for 3 months before my friends translate the song for me.
Later, I'd like to make Pingtype for Japanese (Monoeyes) and Mongolian (Nine Treasures). I like the way that punk and metal music is making traditional folk languages and culture relevant again.
When scraping the Bible data, I also found several characters missing from UTF-8 that were replaced by inline JPGs in the source text.
I checked a physical paper copy, and confirmed with Richard Cook from the Unicode Consortium that these characters need to be added.
However, I'm currently too busy applying for jobs in New Zealand to write that proposal.
I hope that I can find a job that will allow me to continue this kind of side project, and lead to a permanent resident visa in a country where I don't have to join an army to push away foreigners, but where I can welcome people from all nations and cultures.
Figure 11 - Non-Mandarin Chinese Dialects
Comparing the dialects to other world languages also gives an idea of the scale. Facebook has a translation for Japanese (Kansai), despite the population being a third of the size of the number of speakers of Minnan/Hokkien/Taiwanese/台語.
There is no Google Translate for 台語, but I'm a fan of 滅火器 Fire EX. and I want to understand their lyrics.
Therefore I added basic support for 台語 into Pingtype, and I wrote another script that looks up the words from their lyrics in the Bible and hymn book.
From the bilingual data, I can then build a dictionary. I also included some data from Maryknoll and Taigi FHL.
I've made one example video with the help of some friends translating, but I hope to continue developing Pingtype so I don't have to wait for 3 months before my friends translate the song for me.
Later, I'd like to make Pingtype for Japanese (Monoeyes) and Mongolian (Nine Treasures). I like the way that punk and metal music is making traditional folk languages and culture relevant again.
When scraping the Bible data, I also found several characters missing from UTF-8 that were replaced by inline JPGs in the source text.
I checked a physical paper copy, and confirmed with Richard Cook from the Unicode Consortium that these characters need to be added.
However, I'm currently too busy applying for jobs in New Zealand to write that proposal.
I hope that I can find a job that will allow me to continue this kind of side project, and lead to a permanent resident visa in a country where I don't have to join an army to push away foreigners, but where I can welcome people from all nations and cultures.
|